Deployment
(NOTE: This is a work in progress)
The intent of this page is to start to describe what a production deployment of API Umbrella looks like.
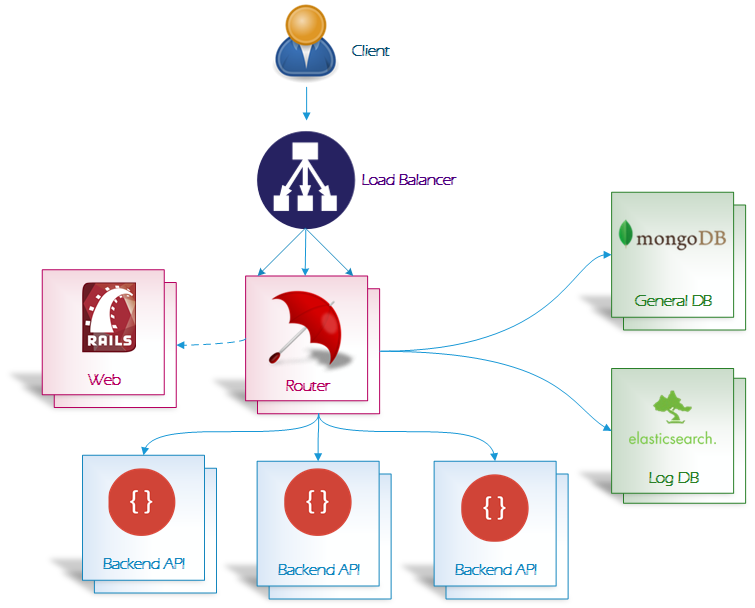
A production deployment consists of three types of nodes:
- API Umbrella Router (including a gatekeeper and optionally a static website and/or admin portal)
- MongoDB nodes for storing configuration and operational data
- ElasticSearch nodes for gathering usage analytics
The embedded MongoDB and ElasticSearch servers included in the all-in-one package should not be used in a production deployment. Instead, these two services should each be configured independently according to their respective best practices.
(Are we recommending the all-in-one package for setting up the router in a production deploy?)
The Router is the core of the API Umbrella deployment. In production, there should be two or more of them, fronted by a Load Balancer. It is essentially a stateless component, although it does queue up usage data locally before syncing with MongoDB/ElasticSearch. So, in the event that it is not shut down cleanly, there is the potential to lose under a minute of usage data.
In the current architecture, there are a lot of moving parts that make up the router:
- Various Nginx listeners
- Offering routing between gatekeeper and admin web interface
- Load balancing across internal gatekeeper listeners
- Configurable external load balancing across API backends
- Gatekeeper nodejs server, which enforces API usage policy
- Redis data store, which temporarily stores local data to minimize network calls for each request
- Varnish cache for caching API results
However, for deployment purposes, they should all be treated as a single component. Each router has its own independent set of these subcomponents to minimize the amount of network communication required on each request. These elements can not and should not be split out onto their own nodes.
The /etc/api-umbrella/api-umbrella.yml configuration file for the router nodes should look something like the following:
services:
- router
web:
admin:
initial_superusers:
- <insert email of admin here>
gatekeeper:
workers: <number of CPU cores>
nginx:
workers: <number of CPU cores>
mongodb:
url: "mongodb://<user>:<password>@<host1>:<port1>,<host2>:<port2>[,...]/<database>"
elasticsearch:
hosts:
- "http://<server1>:<port1>"
- "http://<server2>:<port2>"
...
- The services list indicate which components should be running on this machine.
- The initial_superusers are the email addresses of the users who will be granted admin privileges in the admin console.
- The workers for nginx and gatekeeper indicate how many worker threads to spool up for processing requests. These two values should always match up and should correspond to the number of CPU cores on the machine that you're deploying to. (default value is 4)
- The mongodb and elasticsearch configuration point to the general db and log db servers, respectively.
You will need a hardware or software load balancer for distributing and failing over traffic across your router nodes. Possible software alternatives include HAProxy or, when running in AWS, Amazon Elastic Load Balancer (ELB).
This represents a Ruby on Rails admin application, which may be co-located on the router nodes or deployed to its own dedicated set of servers. It is represented by the web service in the api-umbrella.yml config file.
This is the primary persistence store for API Umbrella. It stores all configuration, rules, and usage information for the purposes of enforcing usage policies. In production, you will want to deploy MongoDB to a 3-node replica set, at a minimum (which is resilient to the failure of a single node).
The log database records the actual usage information for the API, which is used to present analytics in the web application. In a production install, you would also need at least 3 ElasticSearch nodes to be resilient to a single-node failure.